고정 헤더 영역
상세 컨텐츠
본문
반응형
오늘 실습에서 배운 것 (What I Learned)

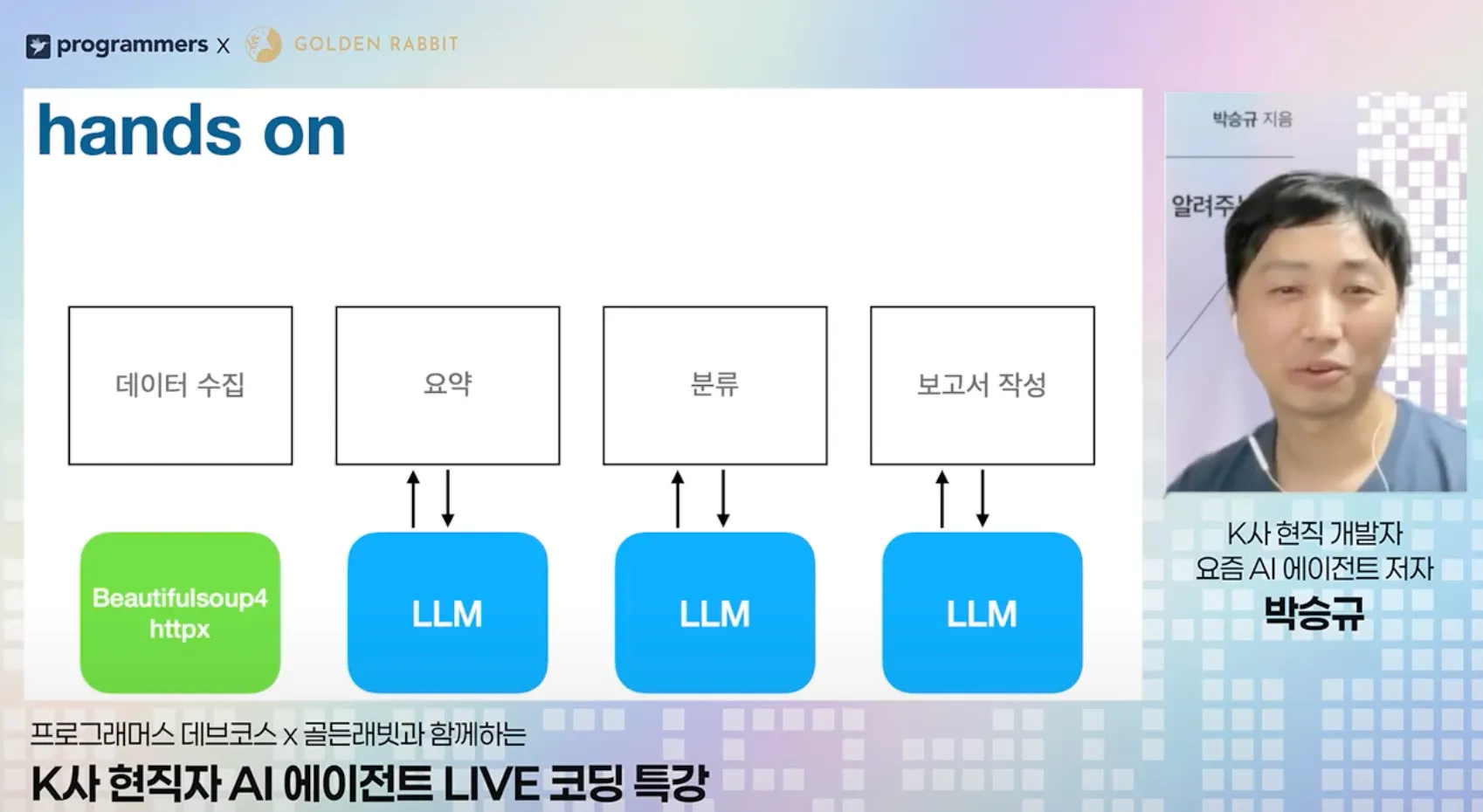
오늘 실습의 핵심은 단순히 챗봇과 대화하는 것이 아니라, 코드를 통해 LLM에게 일을 시키고 결과를 받아 다시 코드로 처리하는 '파이프라인'을 만드는 과정이었다.
(1) 하이브리드 접근 방식의 효율성 모든 것을 AI에게 맡기는 게 정답은 아니라는 점을 배웠다.
- 웹 크롤링(데이터 수집): httpx와 BeautifulSoup 같은 기존 파이썬 라이브러리를 쓰는 게 훨씬 빠르고 정확하다.
- 데이터 가공(요약/분류): 문맥 이해가 필요한 이 부분에서 비로소 LLM(Gemini)을 호출한다. 이렇게 역할 분담을 해야 비용(토큰)도 아끼고 속도도 높일 수 있다.
(2) 데이터 전처리의 중요성 (Garbage In, Garbage Out) BeautifulSoup으로 HTML을 파싱할 때, 무작정 텍스트를 긁어오는 게 아니라 data-tiara-layer="article_body"처럼 본문이 담긴 태그만 콕 집어서 가져오는 과정이 인상적이었다. 쓸데없는 광고나 메뉴 텍스트가 들어가면 AI가 요약을 제대로 못 하거나 엉뚱한 소리를 할 수 있기 때문이다. AI 성능의 반은 데이터 전처리에서 나온다는 말이 실감 났다.
(3) 프롬프트 엔지니어링과 페르소나 부여 단순히 "요약해줘"라고 하는 것보다, 시스템 프롬프트에 "너는 뉴스 요약 전문가야"라고 역할을 주고, "핵심만 두세 문장으로"라고 제약 조건을 걸었을 때 결과물의 퀄리티가 확연히 달라졌다. LangChain의 ChatPromptTemplate을 쓰면 이 형식을 코드 레벨에서 깔끔하게 관리할 수 있다는 점도 배웠다.
(4) JSON을 활용한 데이터 보존 중간 결과물을 계속 JSON 파일로 저장하면서 진행했다. 에이전트가 도중에 멈추더라도 처음부터 다시 크롤링할 필요 없이, 저장된 파일부터 작업을 이어갈 수 있게 설계하는 것이 실무에서 안정성을 위해 꼭 필요할 것 같다.
실습 과정에서의 인사이트 (Insights)
- 에이전트는 결국 '도구'를 쓰는 AI다: 이번 실습에서는 코드로 미리 정의된 함수(크롤러)를 실행했지만, 나중에는 AI가 스스로 "지금은 검색이 필요하군"이라고 판단해서 검색 도구를 꺼내 쓰는 수준까지 가야 진정한 에이전트라고 할 수 있을 것 같다.
- 구조화된 출력의 필요성: LLM은 기본적으로 줄글을 뱉어내는데, 이걸 우리가 원하는 카테고리(정치, 경제 등)로 딱 맞춰서 받으려면 프롬프트에 강력한 제약("반드시 주어진 보기 중에서만 골라")을 걸어야 한다. 그래야 나중에 코드로 if category == '경제': 같은 로직을 짤 수 있다.
아쉬운 점 및 더 공부해볼 내용 (Next Steps)
(1) 단방향 프로세스의 한계 지금 코드는 [수집 -> 요약 -> 분류 -> 저장]이 일직선으로만 흐른다. 만약 중간에 뉴스가 너무 짧아서 요약이 실패하거나, 본문 추출이 안 됐을 때는 그냥 에러를 뱉거나 넘어가 버린다. -> 해결 방안: LangGraph를 공부해야 한다. 실패하면 다시 시도하거나, 다른 방법으로 우회하는 '루프(Loop)' 구조를 만들려면 LangChain의 체인 방식만으로는 부족함을 느꼈다.
(2) 속도 문제 뉴스 10개를 처리하는데 순차적으로(for loop) 돌리다 보니 시간이 꽤 걸렸다. -> 해결 방안: 비동기 처리(AsyncIO)를 적용해서 10개 뉴스를 동시에 요약 요청을 보내면 훨씬 빨라질 것 같다.
(3) 멀티모달 확장 이번엔 텍스트만 처리했지만, 뉴스 기사에 포함된 도표나 사진도 같이 분석해서 "이 사진은 시위 현장입니다"라고 설명해주는 기능도 넣어보고 싶다.
총평
그동안 이론으로만 듣던 "AI 에이전트"를 아주 기초적인 형태지만 직접 내 손으로 구현해봤다는 점이 가장 컸다. 웹상의 지저분한 데이터를 AI가 먹기 좋게 다듬고(전처리), AI가 처리한 결과를 다시 사람이 보기 좋게 만드는(후처리) 전체 흐름을 이해하는 데 큰 도움이 되었다.
반응형
'AI' 카테고리의 다른 글
| [COEX AI Summit 참관 보고서]생성형 AI를 넘어, 행동하는 에이전트(Agent) 시대로의 전환 (0) | 2025.11.22 |
|---|





댓글 영역